파이썬은 모든 것이 객체(Object)이어서, 그 속성이 mutable(가변) 과 immutable(불변)으로 구분된다.
mutable - 변경되는 객체 (객체의 상태를 변경할 수 있음) immutable - 변경되지 않는 객체 (객체의 상태를 변경할 수 없음
변경이 되는mutable 객체의 종류는 list, set, dictionary정도가 있고 변경이 되지 않는immutable 객체의 종류는 int, float, tuple, str, bool 이있습니다.
이러한 개념을 잘 이해해야하는 이유는 깊은복사와 얕은복사를 이해하는데 필수적이기 때문이다. 파이썬에서는immutable 객체의 값이 같은 경우에 변수에 상관없이 동일한 곳을참조합니다. mutable (값이 변경될 수 있는) 객체의 경우에는 모든 객체를 각각 생성해서 참조해 줍니다.
## List
>>> a = [1,2]
>>> b = a #b = [1,2]
>>> a == b #a = [1,2] , b = [1,2]
True
>>> b.append(3) #b = [1,2,3]
>>> a == b #a = [1,2,3] , b = [1,2,3]
True
## Dict
>>> a = {1:'a'}
>>> b = a #b = {1:'a'}
>>> a == b #a = {1:'a'} , b = {1:'a'}
True
>>> b[2] = 'b' #b = {1:'a',2:'b'}
>>> a == b #a = {1:'a',2:'b'} , b = {1:'a',2:'b'}
True
mutable 객체들은 값이 변경될 때 주소가 참조하는 값도 변경되는것을 확인할 수 있었다.
immutable(불변)
Immutable 데이터 타입
int
float
demical
bool
string
tuple
range
## Int
a = 1 #1
>>> id(a)
140729439544144
>>> a += 1 #2
>>> id(a)
140729439544176
## String
a = 'a' #a
>>> id(a)
1985199052704
>>> a += 'b' #ab
>>> id(a)
1985209620944
## Tuple
>>> a = (1,2) #(1,2)
>>> id(a)
1985209935624
>>> a += (3,) #(1,2,3)
>>> id(a)
1985209858448
immutable 에 속한 객체들은 값이 변경이될떄 객체가 변하는것을 확인 할 수 있습니다. 여기에 속한 객체들은 call by value 의 속성을 띄고있습니다.
## Int
>>> a = 1
>>> b = a #b = 1
>>> a == b #a = 1 , b = 1
True
>>> b += 1 #b = 2
>>> a == b #a = 1 , b = 2
False
## String
>>> a = 'a'
>>> b = a #b = 'a'
>>> a == b #a = 'a' , b = 'a'
True
>>> b += 'b' #b = 'ab'
>>> a == b #a = 'a' , b = 'ab'
False
## Tuple
>>> a = (1,2)
>>> b = a #b = (1,2)
>>> a == b #a = (1,2) , b = (1,2)
True
>>> b += (3,) #b = (1,2,3)
>>> a == b #a = (1,2) , b = (1,2,3)
False
immutable 객체들은 값이 변경되는것이 새로운 객체로생성이 되기떄문에 변경이 일어날떄 기존 객체는 변하지 않습니다.
양방향암호화 : 암호화와 복호화과정을 통해 송.수신간 주고받는 메시지를 안전하게 암.복호화하는 과정
단방향암호화 : 해싱(Hashing)을 이용한 암호화 방식으로 양방향과는 다른 개념으로, 평문을 암호문으로 암호화는 가능하지만 암호문을 평문으로 복호화 하는 것은 불가능.
양방향 암호화(대칭/비대칭 Key)
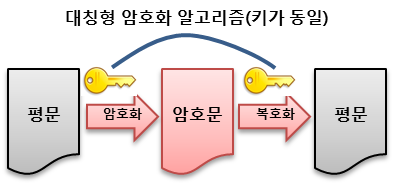
대칭키 : 같은 키를 이용하여 메시지를 암.복호화 하는 것
비대칭키 : 메시지를 암호화 하는 키와 복호화 하는 키가 다름 - 암호화 알고리즘에 따라 사용방식이 다를수도 있다 - 전자서명을 위한 알고리즘에서는 Private Key로 메시지를 서명하고, Public Key로 검증 - 메시지 교환에서는 Public Key로 메시지를 암호화하고 Private Key로 복호화한다.
1. 대칭키 암호화
종류 : AES128, AES256, SEED(국내표준)
암.복호화 키가 같음
문제점은 수신측에 키를 전달하는 과정에서 유출될 우려가 있음
스트림기반, 블록기반의 암호화로 나눌수 있음
1-1. 스트림기반 암호화
비트단위로 암호화하는 방식.
LFFSR, MUX generator 등의 스트림기반 암호화 알고리즘
속도가 빠르고 오류 전파 현상이 없다는 장점
주로 오디오/비디오 스트리밍 시 사용
1-2. 블록기반 암호화
블록 단위로 암호화를 수행하는 방식
문자열 단어 하나하나를 블록으로 나누어 암호화하는 과정
DES, AES, IDEA, SEED 등의 블록기반 암호화 알고리즘
2. 비대칭키 암호화
종류 : DSA(전자서명), RSA(메시지 암.복호화)
대칭키에 비해서는 느리다는 단점이 있음
키생성시 Private Key와 Public Key 2개의 키가 도출되며, Public Key는 공개해도 문제가 되지 않는다.
인수분해, 이산대수, 타원곡선 암호화로 나뉨
2-1. ECC(Elliptic Curve Cryptography)
타원곡선 암호화로써 RSA에 비해 짧은 길이의 키를 사용하면서도 비슷한 수준의 안정성을 제공
비트코인 및 이더리움에서 ECC알고리즘을 이용
2-2. ECC 기반의 암호화
ECDSA(Elliptic Curve Digital Signature Algorithm) : 전자서명(ECC 암호화 알고리즘을 전자서명에 사용한 것)
ECDH(Elliptic Curve Diff-Hellman) : 키교환 알고리즘(자신의 Private Key와 상대방의 Public Key를 사용하여 공통된 Secret 키를 도출)
robots.txt는 웹사이트에서 크롤링하며 정보를 수집하는 검색엔진 크롤러(또는 검색 로봇)가 액세스 하거나 정보수집을 해도 되는 페이지가 무엇인지, 해서는 안 되는 페이지가 무엇인지 알려주는 역할을 하는 .txt (텍스트) 파일입니다. robots.txt 파일은 검색엔진 크롤러가 웹사이트에 접속하여 정보 수집을 하며 보내는 요청(request)으로 인해 사이트 과부하되는 것을 방지하기 위해 사용됩니다. 그리하여 robots.txt에서 액세스가 허용되지 않은 디렉토리라면 원칙적으로 크롤링하지 않습니다.
Robots.txt를 왜 적용해야 할까?
검색엔진 최적화 측면에서 보았을 때 robots.txt 파일을 적용해야 하는 이유는 크게 세 가지가 있습니다. 첫 번째는 앞서 간략하게 언급한 것 같이, 검색엔진 크롤러의 과도한 크롤링 및 요청으로 인한 과부하 방지를 위해서입니다. 크롤러의 정보 수집 및 크롤링을 제한함으로써 불필요한 요청을 줄이고, 서버에서 처리해야 하는 요청을 줄여 과부하로 인한 문제가 생기는 것을 방지할 수 있습니다.
두 번째는 검색엔진 크롤러의 일일 요청 수를 뜻하는 크롤 버짓 (또는 크롤링 예산 – Crawl budget) 낭비 방지를 위해서입니다. 검색엔진은 웹사이트에 방문해 정보를 수집할 때 웹사이트의 규모를 포함한 여러 가지 요소들을 고려하여 하루에 얼마나 많은 페이지를 방문 및 수집할지 설정합니다. 예를 들어 웹사이트에 1,000개의 페이지가 있고, 검색엔진이 일간 2,000 건의 요청 수를 보낸다고 한다면, 웹사이트에서 새로운 콘텐츠가 발행되거나, 업데이트가 있었을 경우 반나절이면 검색엔진이 변경사항에 대해 인지를 하게 된다고 볼 수 있습니다. 만약 robots.txt 파일에서 크게 중요하지 않거나 크롤링되지 말아야 하는 페이지를 지정하지 않는다면, 일일 크롤 버짓이 낭비될 수 있습니다. 결과적으로 정작 중요한 업데이트 또는 새로운 페이지가 검색엔진 결과에 반영되지 않거나 빠르게 색인되는데 불리합니다.
세 번째는 robots.txt를 이용해 검색엔진 크롤러에게사이트맵 (sitemap.xml)의 위치를 제공하여 웹사이트의 콘텐츠가 검색엔진에게 더 잘 발견될 수 있도록 하기 위해서입니다. 물론 구글 서치 콘솔이나 네이버 서치 어드바이저와 같은 웹마스터 도구를 이용해 사이트맵을 검색엔진에 제출할 수 있지만, robots.txt에 사이트맵 디렉토리를 언급함으로써 사이트맵이 구글과 네이버를 포함한 다른 검색 검색엔진 크롤러에게 빠르게 발견될 수 있습니다.
추가적으로, SEO 측면에서의 이유는 아니지만 robots.txt를 창의적으로 이용하여 브랜딩 측면에서 좋은 이미지를 구축할 수 있습니다. 검색엔진 크롤러는 robots.txt의 표준 구문을 인식하고, 주석 처리된 문자열을 무시하기 때문에 이 특성을 이용하여 몇몇 글로벌 웹사이트들은 긍정적인 브랜드 이미지를 만드는데 robots.txt 파일을 사용하기도 합니다. 대표적으로는 에어비앤비 홈페이지를 예로 들 수 있다.
Robots.txt 작성
1. Robots.txt 작성방법
robots.txt 작성에 앞서, 먼저 robots.txt 파일은 어떤 형식으로 작성되어야 하는지 짚고 넘어가야 합니다. ” .txt”로 끝나는 명칭에서 이미 눈치채셨을지 모르겠지만, robots.txt은 기본적으로 텍스트 파일( .txt )로 작성이 되어야 합니다. 그러기 위해서는 텍스트 파일을 편집할 수 있는 툴 (메모장, 텍스트 편집기, MS 워드) 등으로 robots.txt 파일을 작성한 뒤, .txt 파일 형식으로 저장하여야 합니다. 또한 robots.txt는 사람이 아닌 검색엔진 크롤러 (예: 구글봇, 네이버 예티, 빙봇 등)가 읽고 인식해야 하는 파일이기 때문에 정해진 형식과 문법에 따라 작성해야 합니다. 검색엔진 크롤러 별로 robots.txt 파일을 해석하는 방식이 조금씩 차이가 있다고 알려져 있으나, 기본적인 문법은 다르지 않습니다. 가장 기본적인 robots.txt 파일은 아래와 같은 형식을 가집니다.
#robots.txt 예시 - 기본 형식
User-agent: *
Disallow: /forbidden/
robots.txt 는 기본적으로 두 가지의 정보를 포함합니다. 위의 robots.txt 예시처럼 어떤 검색엔진 크롤러를 지정할 것인지 (User-agent 값), 그리고 어떤 디렉토리를 제한할 것인지 (Disallow 값)에 대한 정보를 지정할 수 있습니다. 위의 robots.txt 기본 형식 예시는 모든 검색엔진 크롤러를 (User-agent: *) 모든 /forbidden/ 서브 폴더 이하 디렉토리의 크롤링을 제한한다 (Disallow: /forbidden/)라는 의미입니다.
robots.txt를 구성하는 요소는 크게 네 가지가 있습니다. 각각의 구성 요소를 모두 포함할 필요는 없지만 “User-agent”는 반드시 포함되어야 합니다.
User-agent: robots.txt 에서 지정하는 크롤링 규칙이 적용되어야 할 크롤러를 지정합니다.
Allow: 크롤링을 허용할 경로입니다 (/ 부터의 상대 경로).
Disallow: 크롤링을 제한할 경로입니다 (/ 부터의 상대 경로).
Sitemap: 사이트맵이 위치한 경로의 전체 URL입니다 (https:// 부터 /sitemap.xml 까지의 전체 절대경로 URL).
User-agent 이름은 검색엔진마다 모두 다릅니다. 가장 대표적으로 알려져 있는 구글 (Googlebot), 네이버 (Yeti), 빙(Bingbot), 야후 (Slurp) 외에도 각 검색엔진마다 User-agent 이름을 확인하여야 합니다. 아래는 자주 쓰이거나 영향력이 있는 서치 엔진별 크롤러 User-agent 이름 모음입니다. 웹사이트 크롤링 규정을 적용할 검색엔진 크롤러명을 지정하실 때 참고하시길 바랍니다.
구글: Googlebot
네이버: Yeti
다음: Daum
빙: Bingbot
덕덕고: DuckDuckBot
위 리스트에 포함된 검색엔진 크롤러 말고도 검색엔진별 크롤러의 이름은 모두 다르며, 검색엔진 업데이트 또는 리브랜딩의 이유로 크롤러 이름이 바뀌는 경우도 드물지만 종종 있는 일입니다. 그렇기에 robots.txt를 작성하기 전에 검색을 통해 검색엔진별 크롤러 이름을 먼저 확인이 필요할 것이다.
2. Robots.txt 문법과 예시
앞서 잠시 언급했지만, robots.txt는 사람이 아닌 검색엔진 크롤러를 위한 파일이기 때문에 특정한 형식과 문법을 지켜 작성해야 합니다. 가장 기본적인 형태의 “User-agent”와 “Disallow”를 기본 뼈대로 여러 조합을 통해 특정 크롤러 별, 특정 디렉토리 별로 크롤링 제한을 적용할 수 있습니다.
robots.txt 파일을 작성할 때 가장 기본적으로 명심하셔야 할 것은, robots.txt 파일에서 특정하게 명시하지 않은 크롤러와 디렉토리는 모두 크롤링이 가능한 것으로 간주됩니다. 그렇기 때문에 특별한 이유가 있는 것이 아니라면 따로 크롤링이 가능한 검색엔진 크롤러 또는 디렉토리를 지정할 필요가 없습니다.
아래 robots.txt 예제는 가장 기본적인 형식인모든 또는 특정 크롤러의 특정 폴더 이하 제한 문법입니다. 아래와 같이 모든 크롤러 (*) 또는 특정 크롤러명을 입력하면 됩니다.
# 대상: 모든 크롤러
# 제한 디렉토리: /do-not-crawl-this-folder/ 이하
User-agent: *
Disallow: /do-not-crawl-this-folder/
# 대상: 네이버 크롤러 (Yeti)
# 제한 디렉토리: /not-for-naver/ 이하
User-agent: Yeti
Disallow: /not-for-naver/
위의 기본 형식에서는 한 가지, 또는 모든 크롤러를 한 가지 디렉토리만 제한하는 문법이었는데요, 만약복수의 크롤러가, 특정 디렉토리에서 크롤링하는 것을 제한하고 싶다면아래 예제와 같이 한 줄에 하나의 User-agent를 여러 개 적고, 제외할 디렉토리를 지정하면 됩니다. 여기서 주의해야 할 점은, 제한하고자 하는 크롤러를 모두 적은 뒤 디렉토리를 지정하는 “Disallow” 라인을 작성해야 한다는 점입니다.
# 대상: 네이버 크롤러 (Yeti) & 덕덕고 크롤러 (DuckDuckBot) & 다음 크롤러(Daum)
# 제한 디렉토리: /not-for-naver-and-duckduckgo-and-daum/ 이하
User-agent: Yeti
User-agent: DuckDuckBot
User-agent: Daum
Disallow: /not-for-naver-and-duckduckgo-and-daum/
그렇다면다수의 크롤러를 제한하되, 제한하는 크롤러마다 다른 디렉토리를 차단하고 싶은 경우는 아래 예제와 같이 User-agent를 지정해준 뒤 개별적인 디렉토리를 지정해주면 됩니다.
# 대상: 네이버 크롤러 (Yeti)
# 제한 디렉토리: /not-for-naver/ 이하
# 대상: 덕덕고 크롤러 (DuckDuckBot)
# 제한 디렉토리: /not-for-duckduckgo/ 이하
User-agent: Yeti
Disallow: /not-for-naver/
User-agent: DuckDuckBot
Disallow: /not-for-duckduckgo/
예를 들어 네이버와 덕덕고는 같은 디렉토리 세 가지를 제한하고, 다음(Daum)은 두 가지 디렉토리를 제한하고 싶다면 아래와 같이 작성하여야 합니다.
# 대상: 네이버 크롤러 (Yeti) & 덕덕고 크롤러 (DuckDuckBot)
# 제한 디렉토리 1: /not-for-naver-and-duckduckgo-1/ 이하
# 제한 디렉토리 2: /not-for-naver-and-duckduckgo-2/ 이하
# 제한 디렉토리 3: /not-for-naver-and-duckduckgo-3/ 이하
# 대상: 다음 크롤러 (Daum)
# 제한 디렉토리 1: /not-for-daum-1/ 이하
# 제한 디렉토리 2: /not-for-daum-2/ 이하
User-agent: Yeti
User-agent: DuckDuckBot
Disallow: /not-for-naver-and-duckduckgo-1/
Disallow: /not-for-naver-and-duckduckgo-2/
Disallow: /not-for-naver-and-duckduckgo-3/
User-agent: Daum
Disallow: /not-for-daum1/
Disallow: /not-for-daum2/
앞서 robots.txt 에 지정되지 않은 크롤러와 디렉토리는 크롤링이 가능한 것으로 간주되기에 따로 “Allow” (크롤링 가능 디렉토리) 지정을 하지 않아도 된다고 하였습니다. Allow 디렉토리 지정의 경우 아래 예제와 같이크롤링이 제한된 상위 서브 폴더 이하의 디렉토리 중, 특정 세부 디렉토리를 따로 크롤링 허용하고 싶을 때사용하여야 합니다.
# 대상: 네이버 크롤러 (Yeti)
# 제한 디렉토리: /not-for-naver/ 이하
# 허용 디렉토리: /not-for-naver/only-allow-here/ 이하
User-agent: Yeti
Disallow: /not-for-naver/
Allow: /not-for-naver/only-allow-here/
위의 세부 디렉토리 허용 예제에서 눈치채셨을지도 모르지만, Allow (디렉토리 허용)은 Disallow (디렉토리 차단) 보다 우선권을 갖습니다. 따라서 Allow를 사용하여 세부 디렉토리 크롤링 허용을 지정하게 될 때에는 의도치 않게 Disallow와 상충되지는 않는지 잘 살펴보아야 합니다. 아래는 잘못된 Allow 사용으로 Disallow 지정이 상충된 예시입니다. 아래와 같이 제한 디렉토리보다 상위 디렉토리를 허용하게 된다면, 지정된 제한 디렉토리는 허용 디렉토리와 상충되어 무효 처리됩니다.
# 대상: 네이버 크롤러 (Yeti)
# 제한 디렉토리: /folder-depth-1/folder-depth-2/ 이하
# 허용 디렉토리: /
User-agent: Yeti
Disallow: /folder-depth-1/folder-depth-2/
Allow: /
원하는 크롤링 제한 크롤러와 디렉토리 지정을 마쳤다면, 마지막으로는 사이트맵 위치를 명시해야 합니다. 사이트맵은 “Sitemap:”이라는 형식으로 포함할 수 있으며, 복수의 사이트맵 위치를 명시할 수 있습니다. 사이트맵 위치는 상대 주소를 사용하는 Disallow 또는 Allow 디렉토리와는 다르게, 절대 주소 (전체 URL) 포함해야 합니다. 아래는 사이트맵을 포함한 기본형 robots.txt 파일의 작성 예시입니다.
상황과 목적에 맞게 robots.txt 작성을 모두 마쳤다면 텍스트 파일 (.txt) 로 저장해야 하는데요, 이때 파일명은 반드시 robots.txt 여야 합니다. 또한 업로드는 반드시 웹사이트의 루트 디렉토리 (웹사이트 주소에서 첫번째 '/' 바로 뒤) 에 업로드 되어야 한다. 네이버의 예를 들어보면 https://www.naver.com/robots.txt 에 업로드 되어있다.
데코레이터(Decorator)란 사전적 의미로는 “장식가” 또는 “인테리어 디자이너” 등의 의미를 가지고 있습니다. 이름 그대로, 자신의 방을 예쁜 벽지나 커튼으로 장식을 하듯이, 기존의 코드에 여러가지 기능을 추가하는 파이썬 구문이라고 생각하면 된다.
즉, 함수를 받아 명령을 추가한 뒤 이를 다시 함수의 형태로 반환하는 함수이다. 함수의 내부를 수정하지 않고 기능에 변화를 주고 싶을 때 사용한다. 일반적으로는 함수의 전처리나 후처리에 대한 필요가 있을 때 사용한다. 또한 데코레이터를 이용해, 반복을 줄일고 메소드나 함수의 책임을 확장한다. 본인의 경우에는 파이썬을 학습하면서 새로 정의한 함수의 기능을 측정할 때 사용했다. 즉, 해당 함수가 시작될 때 시간을 측정하고 함수의 기능이 모두 종료된 후에 시간을 측정하여 그 값의 차를 구해 함수의 총 수행시간을 계산하여 출력하는 데코레이터를 만들어 활용했었다.
데코레이터의 구조
함수로 만드는 데코레이터는 일반적으로 아래와 같은 구조를 가지고 있다.
def out_func(func): # 기능을 추가할 함수를 인자로
def inner_func(*args, **kwargs):
return func(*args, **kwargs)
return inner_func
먼저 decorator 역할을 하는 함수를 정의하고, 이 함수에서 decorator가 적용될 함수를 인자로 받는다. python 은 함수의 인자로 다른 함수를 받을 수 있다는 특징을 이용하는 것이다.
decorator 역할을 하는 함수 내부에 또 한번 함수를 선언(nested function)하여 여기에 추가적인 작업(시간 출력) 을 선언해 주는 것이다.
nested 함수를 return 해주면 된다.
클래스형 데코레이터 사용 예제
import datetime
class DatetimeDecorator:
def __init__(self, f):
self.func = f
def __call__(self, *args, **kwargs):
print datetime.datetime.now()
self.func(*args, **kwargs)
print datetime.datetime.now()
class MainClass:
@DatetimeDecorator
def main_function_1():
print "MAIN FUNCTION 1 START"
@DatetimeDecorator
def main_function_2():
print "MAIN FUNCTION 2 START"
@DatetimeDecorator
def main_function_3():
print "MAIN FUNCTION 3 START"
my = MainClass()
my.main_function_1()
my.main_function_2()
my.main_function_3()
decorator를 class로 사용하고 싶다면 위와 같이 __call__ 함수로 decorator 형식을 정의해 주면된다. class의 __call__ 함수로 정의해주는게 nested 함수 형식으로 정의한 것 보다 더 깔끔해 보인다.
데코레이터 실 사용 예제
학생들의 평균을 계산하는 코드를 일단 아래와 같이 작성하였다.
score = [(100, 100), (95, 90), (55, 60), (75, 80), (70, 70)]
def get_avg(score:list):
# 리스트와 반복문을 사용
# 학생별 평균
for index, point in enumerate(score):
print(f'{index+1}번, 평균 : {sum(point)/len(point):.1f}')
만약 위의 함수가 교내 교직원만 사용되어야 하는 함수라서 교직원의 코드를 입력해야만 사용할 수 있다고 가정한다면 교내에서만 사용하는 코드를 확인하고 실행할 수 있는 데코레이터 함수를 선언할 수 있다.
def need_code(func):
def wrapper(*args, **kwargs):
code = "1234"
input_pw = input("비밀번호를 입력하세요 : ")
if input_code == code:
result = func(*args, **kwargs)
else:
result = "잘못된 코드입니다.
return result
return wrapper
위에서 설명했듯 데코레이터를 선언하고 사용하면 결과적으로 wrapper 함수가 실행되는 것이다. input으로 코드를 입력받고 코드가 맞으면 데코레이터를 함수로 전달한 func 죽, get_avg() 함수를 실행하고, 코드가 맞지 않으면 "잘못된 코드입니다." 를 반환한다.
파이썬의 오퍼레이터에 대한 오버로딩을 구현할 수 있도록 돕습니다. 즉, 사용자 정의의 클래스가 빌트인 오퍼레이터 기능을 커스터마이즈해서 사용할 수 있습니다.
예시) 기본 빌트인 타입 중 int와 string은 + 연산이 불가능하죠.
x = int(1)
print(x + '1')
# 결과: TypeError: unsupported operand type(s) for +: 'int' and 'str'
임의의 클래스를 구현하여 매직메소드를 사용하면 int와 string의 + 연산결과를 얻을 수 있습니다.
#int를 부모클래스로 가진다
class Customized(int):
# 👇str input을 받아 + 연산을 하면 str 타입으로 합체
def __add__(self, plus: str) -> str:
return str(self.real) + plus
x = Customized(1)
print(x + '1')
#결과: '11'
인스턴스 생성
가장 유명한 던더 메소드는 아마__init__()일 것입니다. 그리고__init__()과 함께 constructor 역할을 하는__new__()라는 메소드가 있습니다. __new__()라는 메소드는 새로운 인스턴스를 생성하고 (return하고), __init__()이 return된 인스턴스를 인자에 맞게 커스터마이즈(초기화)합니다. __new__()는 static method이며, 일반적인 경우 굳이 오버라이드 하지 않습니다.
형식과 사용법은 아래와 같습니다.
#__new__() 형식
class ClassName:
def __new__(cls, *args, **kwargs):
#...중간 코드...#
return super(ClassName, cls).__new__(cls, *args, **kwargs)
클래스는 객체(Object)를 만들기 위한 방법입니다. 클래스는 변수와 객체 그리고 관련된 기능들을 선언할 수 있습니다. 파이썬에서 클래스를 만들기 위해 'class' 키워드를 사용합니다.
Instance
객체(Object)는 클래스의 생성자를 사용하여 생성합니다. 이 객체를 클래스의 인스턴스라 부릅니다.
Python의 매소드 종류
Python에는 3가지의 매소드 타입이 존재합니다. static매소드, class매소드, instance 매소드. 3가지는 각각 다른 기능을 가지며 필요에 따라 사용해야 합니다.
1. Static 매소드
static매소드는 생성할때 @staticmethod를 명시해줘야 합니다. static 매소드의 가장 중요한 특징은 인스턴스화 하지 않고 매소드를 호출 할 수 있습니다. static 메소드는 독립적으로 사용되기 때문에 다른 속성에 액세스하거나 해당 클래스 내의 다른 메소드를 호출 할 수 없습니다.
class가 있을때 static 매소드를 사용할 수 있고 매소드에 엑세스 하기 위해 특정 인스턴스가 필요하지 않습니다. 예를 들어 Math라는 클래스가 있고 factorial이라는 메서드가있는 경우 static 메소드를 사용할 수 있도록 해당 메소드를 호출하기 위해 특정 인스턴스가 필요하지 않을 수 있습니다.
[ static 매소드의 예제 ]
class Math:
@staticmethod
def factorial(number):
if number == 0:
return 1
else:
return number * MethodTypes.factorial(number - 1)
factorial = MethodTypes.factorial(5)
print(factorial)
2. class 매소드
class 매소드는 static 매소드와 동일한 방식으로 @classmethod를 명시해 줘야 합니다. class 매소드 또한 static 매소드와 마찬가지로 클래스를 인스턴스화 하지 않아도 호출이 가능합니다. 차이점은 다른 메소드 및 클래스 속성에 액세스 할 수있는 기능에 의존하지만 인스턴스 속성은 없습니다.
3. instance 매소드
instance 매소드는 클래스를 인스턴스화 했을때만 호출이 가능합니다. 해당 클래스의 객체가 생성되면 인스턴스 메소드를 호출하고 예약어 self를 통해 해당 클래스의 모든 속성에 액세스 할 수 있습니다.instance 메소드는 새 인스턴스 속성을 creating, getting 및 setting 하고 다른 인스턴스, 클래스 및 정적 메소드를 호출 할 수 있습니다.
class MethodTypes:
name = "Ragnar"
def instanceMethod(self):
# Creates an instance atribute through keyword self
self.lastname = "Lothbrock"
print(self.name)
print(self.lastname)
@classmethod
def classMethod(cls):
# Access a class atribute through keyword cls
cls.name = "Lagertha"
print(cls.name)
@staticmethod
def staticMethod():
print("This is a static method")
# Creates an instance of the class
m = MethodTypes()
# Calls instance method
m.instanceMethod()
MethodTypes.classMethod()
MethodTypes.staticMethod()
self와 cls의 차이점
self, cls의 키워드의 차이점은 오직 매소드 타입에 있습니다.instance 매소드를 사용하면 self 키워드를 사용하고 class 매소드를 사용하면 cls 키워드를 사용합니다. static 매소드는 속성에 접근할 수 없기 때문에 사용하는 키워드가 없습니다.
속성에 접근하기 위한 방법이며 매소드의 종류에 따라 self, cls 키워드를 사용한다고 생각하면 됩니다.
클로저는 어떤 함수의 내부 함수가 외부 함수의 변수(프리변수)를 참조할 때, 외부 함수가 종료된 후에도 내부 함수가 외부 함수의 변수를 참조할 수 있도록 어딘가에 저장하는 함수를 의미합니다. 클로저 함수는 아래의 조건을 충족해야합니다. (프리변수(free variable)는 어떤 함수에서 사용되지만 그 함수 내부에서 선언되지 않은 변수를 의미합니다.)
여기 hello라는 함수가 하나 있습니다. 매개변수로 msg를 받아 message라는 변수에 문자열로 저장하고 내부함수인 say가 message를 print로 출력해줍니다. 그리고 마지막으로 say함수를(함수 실행값이 아닌 함수 자체를)리턴하고 끝납니다. 정말 단순하기 짝이없는 함수지만, 자세히 보시면say 함수가 클로저의 조건을 모두 만족한다는 사실을 알 수 있습니다.
1. 어떤 함수의 내부 함수일 것 - say함수는 hello함수의 내부 함수
2. 그 내부 함수가 외부 함수의 변수를 참조할 것 - say함수는 외부 함수의 message를 참조
3. 외부 함수가 내부 함수를 리턴할 것 - hello함수는 say함수를 리턴
즉, say함수는 클로저가 될 수 있습니다.
def hello(msg):
message = "Hi, " + msg
def say():
print(message)
return say
f = hello("Fox") # 클로저 생성
f() # 실행 결과 : "Hi, Fox" 출력
f( ) 함수를 실행했을 때 "Hi Fox"라는 문자열이 출력되기까지의 과정을 확인해보자면
1. hello함수에 "Fox"를 매개변수값으로 넘겨주며 실행 2. message변수에 매개변수를 이용해 "Hi, Fox"라는 문자열을 저장 3. say함수가 message변수를 참조 4. say함수 리턴 5. f변수가 say함수를 참조 6. f변수 실행(say함수 실행) 7. f변수는 message변수를 출력
위의 4번에서 hello 함수는 역할을 마치고 종료되어 메모리에서도 삭제되었을 것이다. 그러므로 hello 함수 영역의 message 변수도 삭제되었어야 한다. 하지만 어떻게 f함수가 message변수를 참조해 값을 출력한다는 것일까....
이것을 가능케 한 것이 바로클로저입니다. 중첩 함수인 say가 외부 함수인 hello의 변수 message를 참조하기에 message변수와 say의 환경을 저장하는 클로저가 동적으로 생성되었고 f가 실행될때는 해당 클로저를 참조하여 message값을 출력할 수 있는 것입니다. 이 클로저는 f변수에 say함수가 할당될 때 생성됩니다.
이 클로저(Closure)의 영역을 찾아본다면 f.__closure__[0].cell__contents 로 찾을 수 있다. 참고로 저 __closure__ 튜플은 모든 함수 객체가 가지고 있다. 그렇기 때문에 조건을 만족하지 않아 클로저가 생성되지 않았다면, 그 값은 None으로 고정된다.
↘ Closer의 장점
클로저의 가장 큰 장점은 무분별한 전역변수의 남용 방지라고 생각된다. 단순히 생각하면 클로저를 쓰는 대신 전역변수를 선언해 상시 접근 가능하게 만들 수 있지만 이렇게 하면 변수가 섞일수도 있고 변수의 책임 범위를 명확하게 할 수 없는 문제가 생깁니다. 하지만 클로저를 사용하면 각 스코프가 클로저로 생성되므로 변수가 섞일 일도 없고 각 스코프에서 고유한 용도로 이용되므로 책임 범위 또한 명확해지죠.
위의 예시에서는 내부 함수가 1개밖에 없지만 만약 내부 함수가 여러개라면? 그 여러개의 내부 함수에서 접근할 수 있게 각각 전역변수를 만들어 값을 지정한다면 코드가 지저분해지고 변수명도 점점 알아보기 힘들어지겠죠? 이를 방지해주는게 가장 큰 장점이라고 생각합니다.